Building Reliable AI Systems
At Mentiora, we use the same measurement-driven method whether we are tuning a small on-device model or building a large support system.

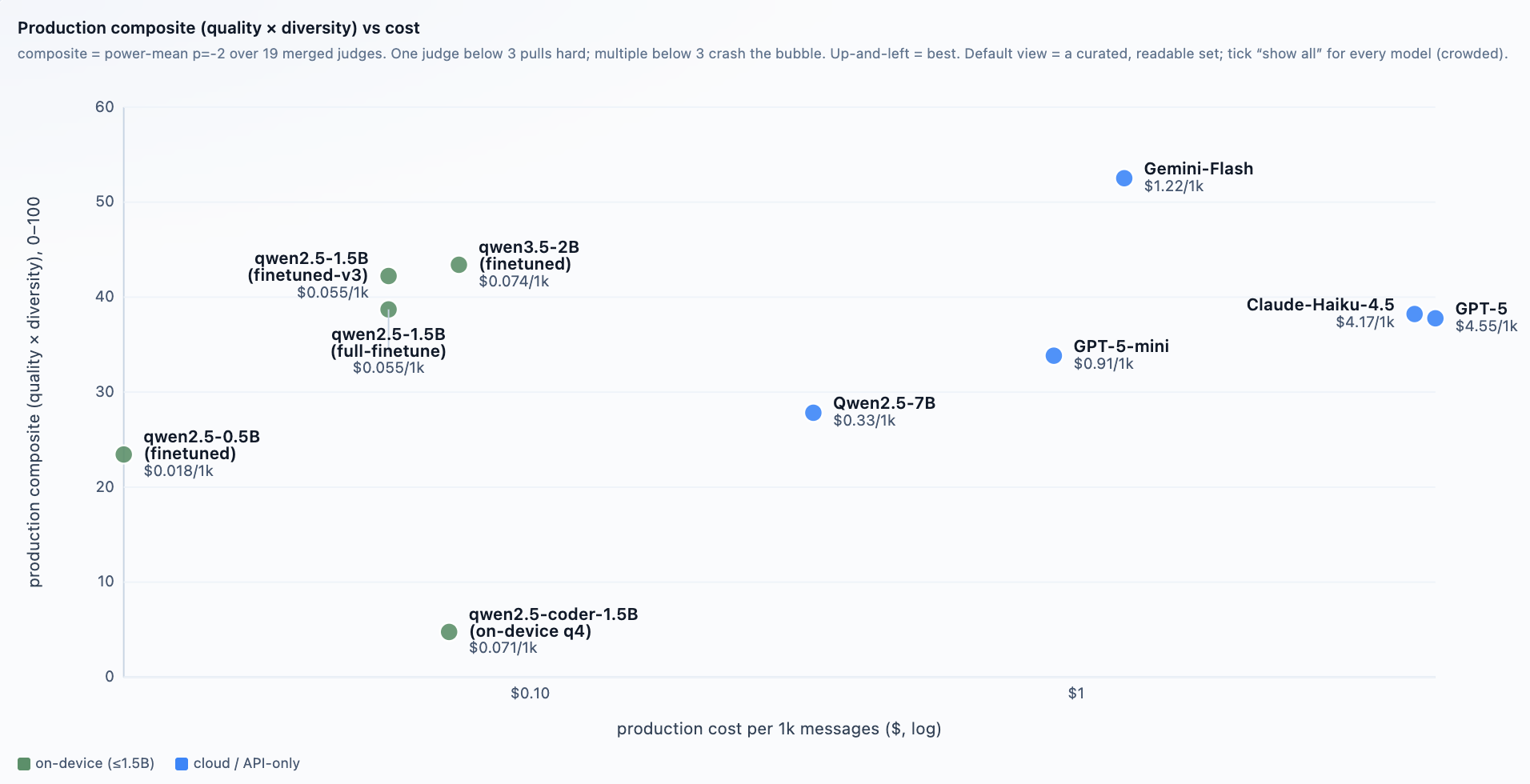

At Mentiora, we build AI systems for many different problems. In a single month, our team might work on two completely different types of software. One project might be a small model designed to run locally on a device. Another project might be a full customer support system that handles complex requests.
On the surface, these projects look very different. They need different architectures and different data. A small local model has strict memory limits. A full support system has a large retrieval pipeline and complex routing.
But internally, we work on them exactly the same way. We approach every problem with the same quality-first method. Because this process does not change, we can build solutions for many use cases, and we can build them quickly.
The method has three steps.
First, we define exactly what a good result means for the specific problem. We do not settle for vague goals like making the system helpful. We write down concrete, testable criteria.
For a customer support system, we define what a complete answer contains. We also define what counts as a failure. We list the exact mistakes the system must never make. It might be forbidden from making up a return policy. It might be required to pass the chat to a human in specific cases. By the end of this step, we have a clear list of rules.
Second, we turn those written rules into a measurement system. We build automated evaluators. These are programs that read the outputs of our AI system and score them against our rules.
Many teams skip this part because it takes time. But we find it makes everything else work. Human review is slow and inconsistent. An automated evaluator can grade thousands of outputs in a few minutes. If the system breaks a rule, the evaluator flags it. If the system gives a correct answer, the evaluator records it.
Third, we iterate fast. Once the measurement is in place, we start building. We make a change to the system. We run the automated evaluator. We look at the score.
We might rewrite the prompt, switch the base model, or clean the training data. Whatever we change, the measurement tells us immediately if we improved the system or made it worse. AI development is tricky. You often fix a problem in one area but break something else. A new prompt might make the system polite but ignore technical rules. Our evaluators catch these mistakes right away. We do not guess. If the score goes up, we keep the change. If it goes down, we discard it.
This is why we can handle such different projects. From the perspective of our method, a small on-device model and a large support system are the same shape of work.
For any project, we start by defining success. We build evaluators to check for those criteria. Then we iterate until the system meets our standards.
The technical details will always change. But the engineering process stays the same. We do not invent a new way of working for every project. This consistency lets a small team move fast. By defining quality and measuring it automatically, we always know exactly what we need to build.
Ready to deploy AI that actually works?
Let us analyze your AI integration and deliver actionable insights on how to improve safety, usefulness, and revenue impact.
Contact Us