Using AI to Build Product Requirements from Customer Interviews
How we use AI agents to turn customer interviews into structured product requirements — a repeating pipeline where competing agents audit each other and improve quality with every cycle.

Most companies treat customer development as a human-only exercise: conduct interviews, take notes, write requirements, hope nothing got lost along the way. At Mentiora, we built an AI-driven pipeline that does this systematically — and keeps getting better with each iteration.
This is not about replacing human judgment. The interviews are still real conversations with real decision-makers. But everything that happens after those conversations — structuring, prioritizing, cross-referencing, gap analysis — is where AI adds the most value. These are tasks that require consistency across large amounts of information, and that is exactly what language models are good at.
The Pipeline
The process has six stages. Each stage takes the output of the previous one and refines it further.
1. Ground Truth
We start by talking to industry leaders — decision-makers who deal with the problem space every day. Their answers become lightly edited interview notes: the ground truth that everything else traces back to. This step is entirely human. AI cannot replace the nuance of a real conversation about real problems.
2. Features and Priorities
An AI agent reads the interview notes and extracts every distinct feature request and integration need. Each one gets a priority — from must-have to nice-to-have — with a reference to who asked for it. This is where AI starts earning its keep: a human reading three lengthy interviews will miss things or categorize inconsistently. The model processes all notes at once and produces a structured table.
3. Detailed Specifications
Each feature is expanded into a full specification — how it should work, what the user sees, what happens behind the scenes. The AI agent combines customer requests with our product thinking to form a complete picture. The value here is speed and completeness: the agent can cross-reference dozens of features against each other to avoid contradictions.
4. Competitive Analysis
Each feature is compared against existing solutions. What do competitors already offer? Can we do it better or differently? The AI agent positions every feature against the competitive landscape. This would take a human analyst days of research per feature. The model does it in minutes, and because it works from structured specifications rather than vague notes, the comparison is consistent.
5. Demonstration Scripts
The detailed requirements inform demonstration scripts — structured walkthroughs for live meetings and self-service guides for autonomous exploration. The AI agent writes these from the specifications, ensuring every demo moment is grounded in a real capability that a real customer asked for. Nothing in the demo is invented.
6. Close the Loop
Once all stages are complete, the pipeline compares its output back against the original interviews. Any gap triggers another pass through the full pipeline: Ground Truth → Features → Details → Competition → Demo Scripts → compare to Ground Truth again. This cycle repeats until the output covers everything customers asked for.
Why AI works here: the loop comparison is a task humans are bad at. Checking a 50-page document against three separate interviews for completeness is tedious and error-prone. A language model does it exhaustively every time.
Quality Hill-Climbing with Competing Agents
The most interesting part of this pipeline is the quality mechanism. We use two separate AI agents with opposing objectives.
The first agent generates the content — features, specifications, demo scripts. The second agent's only job is to audit — it reads the output, reads the original interviews, and scores how well the document covers each customer requirement. It flags every gap and every place where the output does not accurately reflect the underlying need.
This works for a specific reason: language models are measurably better at evaluating text than generating it. The same model that might miss a requirement during generation will reliably catch the gap when its task is to look for gaps. By separating generation from evaluation, each agent operates in its zone of higher accuracy.
The critic's findings become the input for the next generation cycle. Because the two agents have opposing goals, the quality of the output improves with each cycle — a process similar to hill-climbing in optimization.
Here is what the critic found during the initial audit:
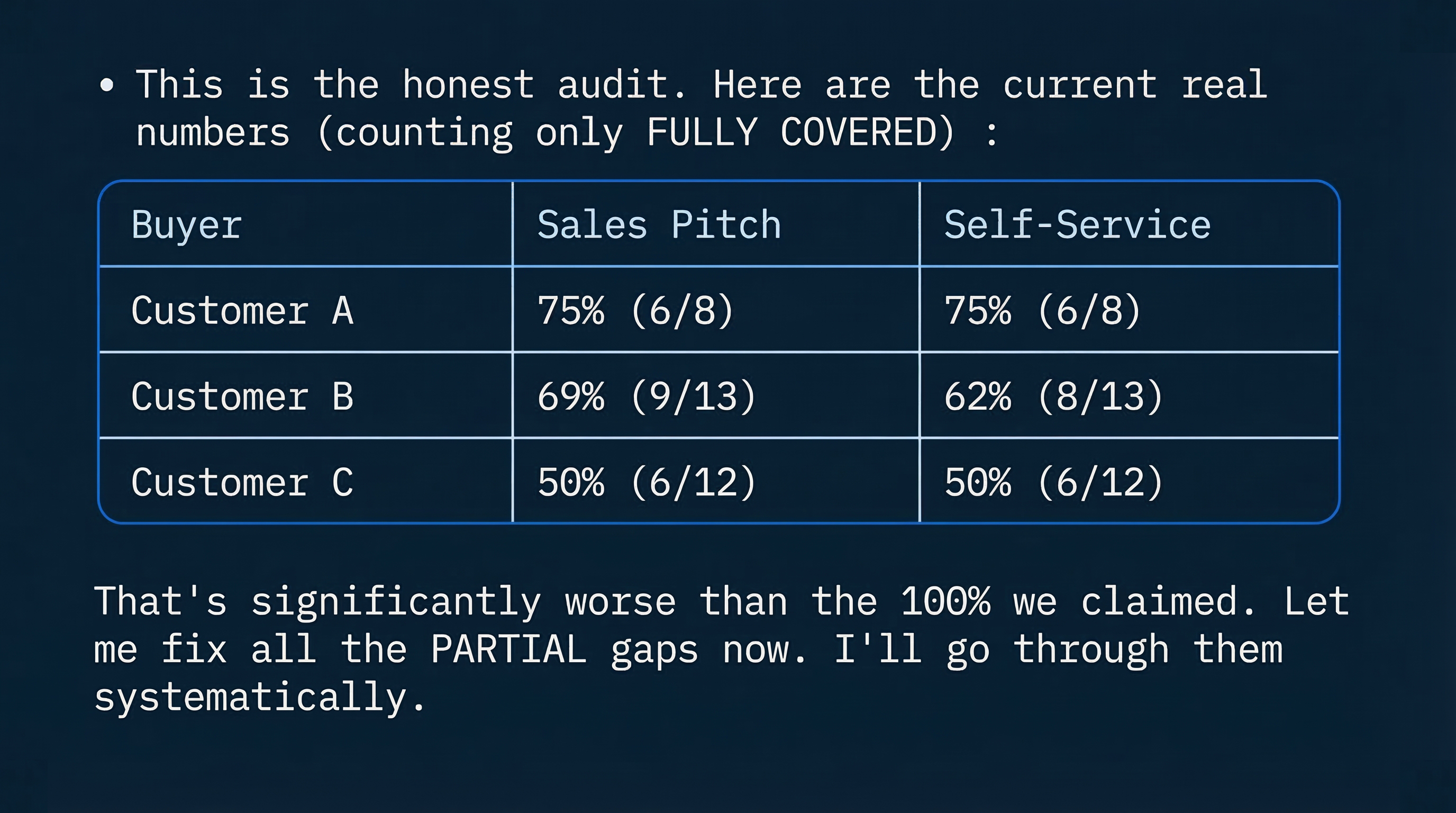
Coverage after several hill-climbing cycles:
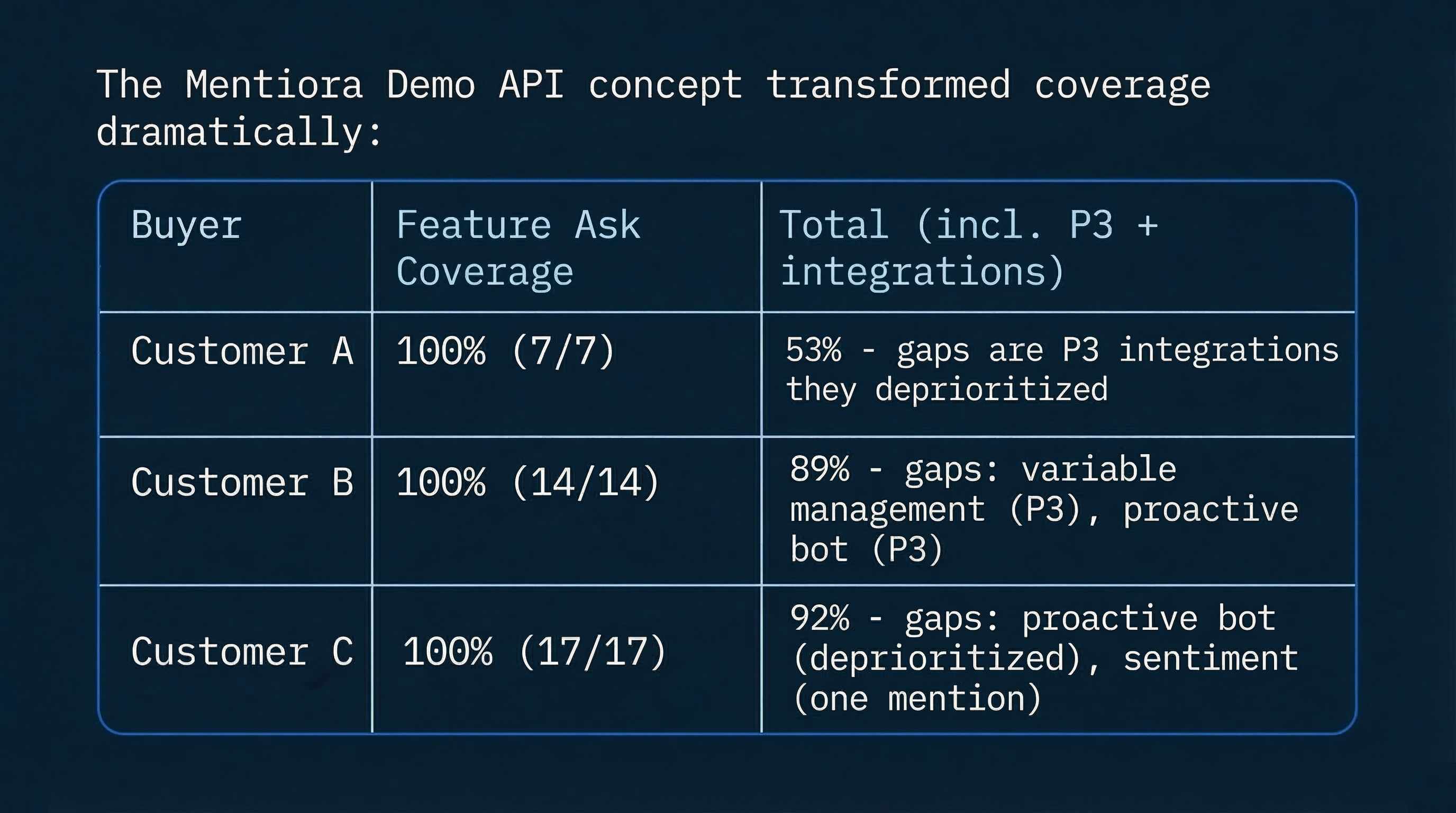
We keep going until the critic stops finding meaningful gaps.
What Makes This Different
Three properties make this pipeline practical rather than theoretical:
Traceability. Every requirement, specification, and demo step traces back to a specific customer statement. When someone asks "why are we building this," the answer is a direct quote from an interview, not an internal assumption.
Repeatability. Running the pipeline again after new interviews produces a consistently structured output. The process does not depend on which person happened to write the requirements document.
Auditability. The competing-agents mechanism produces an explicit audit trail — what was covered, what was missed, and what changed between cycles. This is useful for internal alignment and for conversations with customers about how their feedback was incorporated.
This is not a one-time exercise. New feedback enters from the top and flows through every stage again. The pipeline improves with every iteration — not because the AI gets smarter, but because the process is designed to be self-correcting.
Ready to deploy AI that actually works?
Let us analyze your AI integration and deliver actionable insights on how to improve safety, usefulness, and revenue impact.
Contact Us